
Biostatistics — MCQs

On this page
The relationship between birth rate and maternal hemoglobin is best studied by:
Which of the following statements is true about direct age standardization?
In the estimation of statistical probability, Z score is applicable to:
The two important values necessary for describing the variation in a series of observations are:
Which one of the following tests should be applied to compare mean haemoglobin level of two groups of antenatal mothers?
Which one of the following epidemiologic methods can be used to identify risk factors and estimate the degree of risk?
What is the relative risk of developing pulmonary embolism in users of oral contraceptives as per the information given below?

In a case-control study, 300 women aged 20-45 years suffering from breast cancer were compared with age-matched 300 women without breast cancer. It was observed that 120 women among cases and 60 women among controls were obese. The odds ratio of developing breast cancer among obese women is:
Predictive accuracy of a screening test depends on the following EXCEPT:
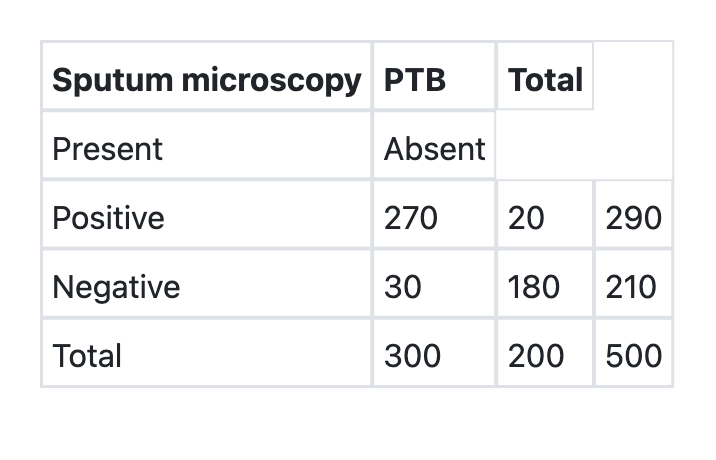
What is the specificity of sputum microscopy in detection of Pulmonary Tuberculosis (PTB) as per the information given below?
Practice by Chapter
Collection and Presentation of Data
Practice Questions
Measures of Central Tendency
Practice Questions
Measures of Dispersion
Practice Questions
Normal Distribution
Practice Questions
Sampling Methods
Practice Questions
Sample Size Calculation
Practice Questions
Hypothesis Testing
Practice Questions
Tests of Significance
Practice Questions
Correlation and Regression
Practice Questions
Survival Analysis
Practice Questions
Multivariate Analysis
Practice Questions
Statistical Software in Research
Practice Questions
Want unlimited practice?
Get full access to all questions, explanations, and performance tracking.
Scan to download app