
Biostatistics — MCQs

On this page
A town in the hills had a mid-year population of 250000 in the year 2021. During the same year, the death registry of the town recorded 1500 deaths due to tuberculosis in 365 calendar days. Given these facts, what is the specific death rate for tuberculosis in the town?
In a town, a study was carried out to determine the role of cigarette smoking in causation of lung cancer. It was found that a total of 7000 people in the town were smokers. Of them, 70 developed lung cancer. In the same town, 3000 people were non-smokers. Of them, 3 developed lung cancer. Given these numbers, what would be the attributable risk to cigarette smoking for lung cancer?
Forty patients with diarrhoeal diseases were studied. Their age distribution is given in the table below : What is the mean age of the patients in this study?
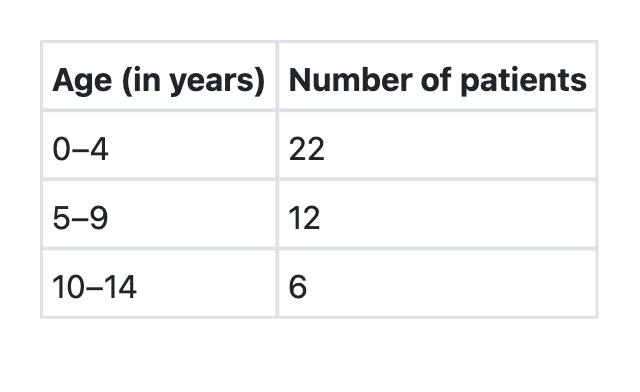
In a normal curve, the area of one standard deviation around the mean includes which of the following per cent of values in a distribution ?
To understand the relationship between weight and height of a group of school children, the data can graphically be best depicted through
For a screening test, 90% specificity means that 90% of non-diseased persons will give a
What is the method of sampling in which the units are picked up at regular intervals from the universe ?
A randomized trial comparing the efficacy of two drugs showed a difference between the two (p value < 0.05). However, in reality the drugs do not differ. This is an example of
In a village, every fifth house was selected for a study. This is an example of
The ability of a test to identify correctly those who do not have the disease is called its
Practice by Chapter
Collection and Presentation of Data
Practice Questions
Measures of Central Tendency
Practice Questions
Measures of Dispersion
Practice Questions
Normal Distribution
Practice Questions
Sampling Methods
Practice Questions
Sample Size Calculation
Practice Questions
Hypothesis Testing
Practice Questions
Tests of Significance
Practice Questions
Correlation and Regression
Practice Questions
Survival Analysis
Practice Questions
Multivariate Analysis
Practice Questions
Statistical Software in Research
Practice Questions
Want unlimited practice?
Get full access to all questions, explanations, and performance tracking.
Scan to download app