
Study Design — MCQs

On this page
A statistician wants to study the effects of a medicine in three groups-humans, animals, and plants. He then selects randomly from these three groups. Which type of sampling is being performed?
A study was undertaken to establish the relationship between the consumption of a vegetarian or non-vegetarian diet and the presence of diseases. Which statistical test should be used?
A group of 80 people is being studied to determine the effect of diet modification on cholesterol levels. To compare the mean cholesterol levels before and after the diet modification in this group, which statistical test should be used?
A study recorded the survival times (in months) of 8 patients diagnosed with pancreatic cancer who received a new chemotherapy regimen. The survival times were: 2, 3, 4, 4, 5, 6, 7, 8 months. What is the median survival time for these patients?
An investigator has conducted a prospective study to evaluate the relationship between asthma and the risk of myocardial infarction (MI). She stratifies her analyses by biological sex and observed that among female patients, asthma was a significant predictor of MI risk (hazard ratio = 1.32, p < 0.001). However, among male patients, no relationship was found between asthma and MI risk (p = 0.23). Which of the following best explains the difference observed between male and female patients?
An investigator studying the effects of dietary salt restriction on atrial fibrillation compares two published studies, A and B. In study A, nursing home patients without atrial fibrillation were randomly assigned to a treatment group receiving a low-salt diet or a control group without dietary salt restriction. When study B began, dietary sodium intake was estimated among elderly outpatients without atrial fibrillation using 24-hour dietary recall. In both studies, patients were reevaluated at the end of one year for atrial fibrillation. Which of the following statements about the two studies is true?
A doctor is interested in developing a new over-the-counter medication that can decrease the symptomatic interval of upper respiratory infections from viral etiologies. The doctor wants one group of affected patients to receive the new treatment, but he wants another group of affected patients to not be given the treatment. Of the following clinical trial subtypes, which would be most appropriate in comparing the differences in outcome between the two groups?
A 23-year-old woman presents to her primary care physician because she has been having difficulty seeing despite previously having perfect vision all her life. Specifically, she notes that reading, driving, and recognizing faces has become difficult, and she feels that her vision has become fuzzy. She is worried because both of her older brothers have had visual loss with a similar presentation. Visual exam reveals bilateral loss of central vision with decreased visual acuity and color perception. Pathological examination of this patient's retinas reveals degeneration of retinal ganglion cells bilaterally. She is then referred to a geneticist because she wants to know the probability that her son and daughter will also be affected by this disorder. Her husband's family has no history of this disease. Ignoring the effects of incomplete penetrance, which of the following are the chances that this patient's children will be affected by this disease?
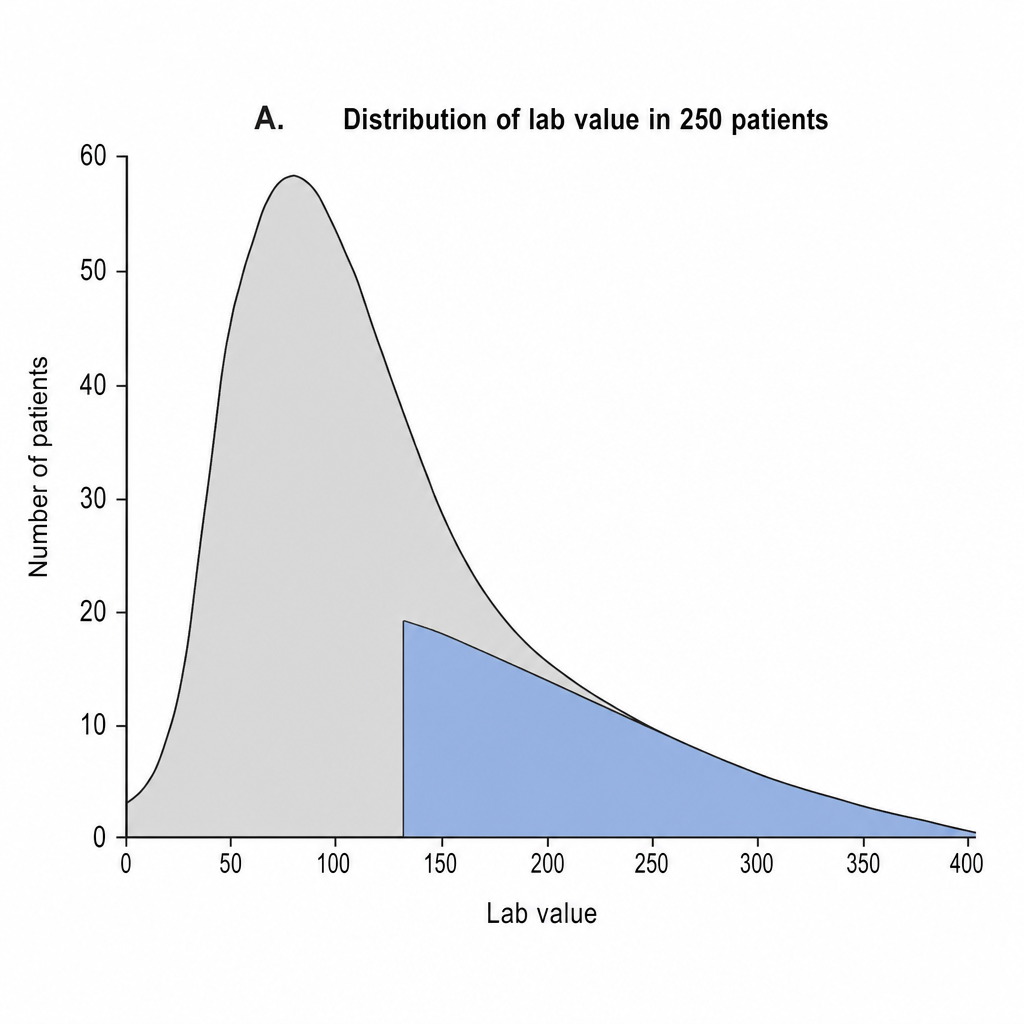
Image A depicts the distribution of the lab value of interest in 250 patients. Given that this is not a normal (i.e. Gaussian) distribution, how many patients are contained in the portion highlighted blue?
A group of researchers recently conducted a meta-analysis of twenty clinical trials encompassing 10,000 women with estrogen receptor-positive breast cancer who were disease-free following adjuvant radiotherapy. After an observation period of 15 years, the relationship between tumor grade and distant recurrence of cancer was evaluated. The results show: Distant recurrence No distant recurrence Well differentiated 500 4500 Moderately differentiated 375 2125 Poorly differentiated 550 1950 Based on this information, which of the following is the 15-year risk for distant recurrence in patients with high-grade breast cancer?
Practice by Chapter
Research question formulation
Practice Questions
Case-control studies
Practice Questions
Cross-sectional studies
Practice Questions
Ecological studies
Practice Questions
Quasi-experimental designs
Practice Questions
Natural experiments
Practice Questions
N-of-1 trials
Practice Questions
Mixed methods research
Practice Questions
Qualitative study designs
Practice Questions
Sampling techniques
Practice Questions
Matching methods
Practice Questions
Longitudinal vs cross-sectional approaches
Practice Questions
Multi-center studies
Practice Questions
Pilot and feasibility studies
Practice Questions
Want unlimited practice?
Get full access to all questions, explanations, and performance tracking.
Scan to download app