
Transcription/translation — MCQs

On this page
Expression of an mRNA encoding for a soluble form of the Fas protein prevents a cell from undergoing programmed cell death. However, after inclusion of a certain exon, this same Fas pre-mRNA eventually leads to the translation of a protein that is membrane bound, subsequently promoting the cell to undergo apoptosis. Which of the following best explains this finding?
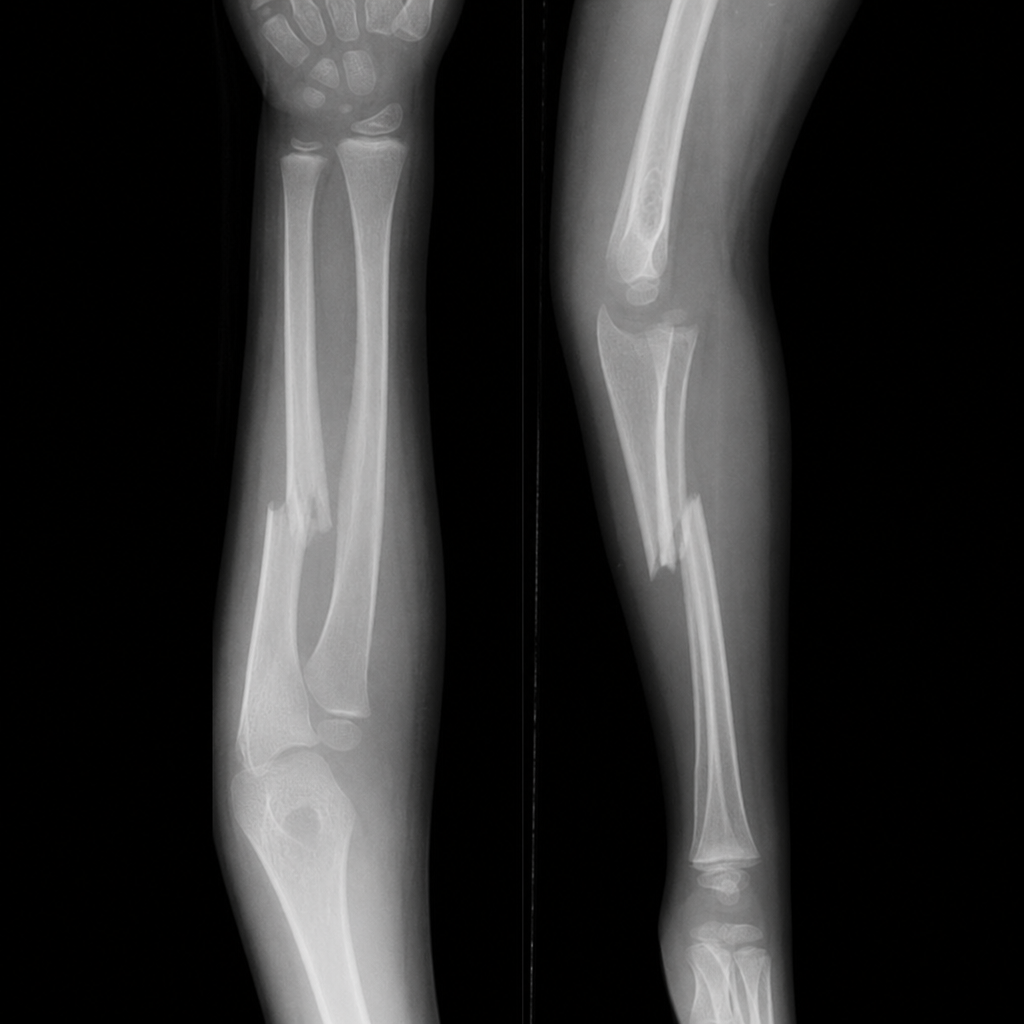
A 3-year-old boy is brought to the physician because of arm pain following a fall that took place 5 hours ago. According to his mother, the boy was running in the yard when he fell and injured his right arm. The boy is crying and clutching his arm. During the past year, he has been brought in 4 other times for extremity pain following falls, all of which have been diagnosed as long bone fractures. He is at the 10th percentile for height and 25th percentile for weight. His temperature is 37.3°C (99.1°F), pulse is 95/min, respirations are 21/min, and blood pressure is 97/68 mm Hg. His right forearm is diffusely erythematous. The patient withdraws and yells when his forearm is touched. His left arm has two small ecchymotic regions overlying the elbow and wrist. A photograph of his face is shown. An x-ray of the right forearm shows a transverse mid-ulnar fracture with diffusely decreased bone density. Which of the following is the most likely cause of this patient's symptoms?
An investigator is studying the rate of wound healing by secondary intention. He performs a biopsy of a surgically debrided wound 1 day and 5 days after the initial surgical procedure. The second biopsy shows wound contraction, endothelial cell proliferation, and accumulation of macrophages. The cells responsible for wound contraction also secrete a protein that assembles in supercoiled triple helices. In which of the following structures does this protein type play an important structural role?
During protein translation, the triplet code of mRNA is read by a ribosome and assisted by elongation and translation factors until it reaches a stop codon (UAA, UAG, or UGA). When a stop codon is reached, a release factor binds, removing the peptide from the active ribosome and completing translation. What will happen if a mutation causes the recruitment of a release factor prior to the completion of a full peptide?
A researcher is trying to decipher how mRNA codons contain information about proteins. He first constructs a sequence of all cytosine nucleotides and sees that a string of prolines is synthesized. He knows from previous research that information is encoded in groups of 3 so generates the following sequences: ACCACCACC, CACCACCAC, and CCACCACCA. Surprisingly, he sees that new amino acids are produced with the first two sequences but that the third sequence is still a string of prolines. Which of the following biochemical principles explains why this phenomenon was observed?
Practice by Chapter
RNA polymerase structure and function
Practice Questions
Promoters and transcription factors
Practice Questions
Initiation of transcription
Practice Questions
Elongation and termination of transcription
Practice Questions
Post-transcriptional modifications
Practice Questions
RNA splicing and alternative splicing
Practice Questions
Translation initiation
Practice Questions
Elongation and termination of translation
Practice Questions
Post-translational modifications
Practice Questions
Protein folding and chaperones
Practice Questions
Regulation of gene expression
Practice Questions
Epigenetic mechanisms
Practice Questions
RNA interference and microRNAs
Practice Questions
Want unlimited practice?
Get full access to all questions, explanations, and performance tracking.
Scan to download app