
Sample Size Calculation — MCQs

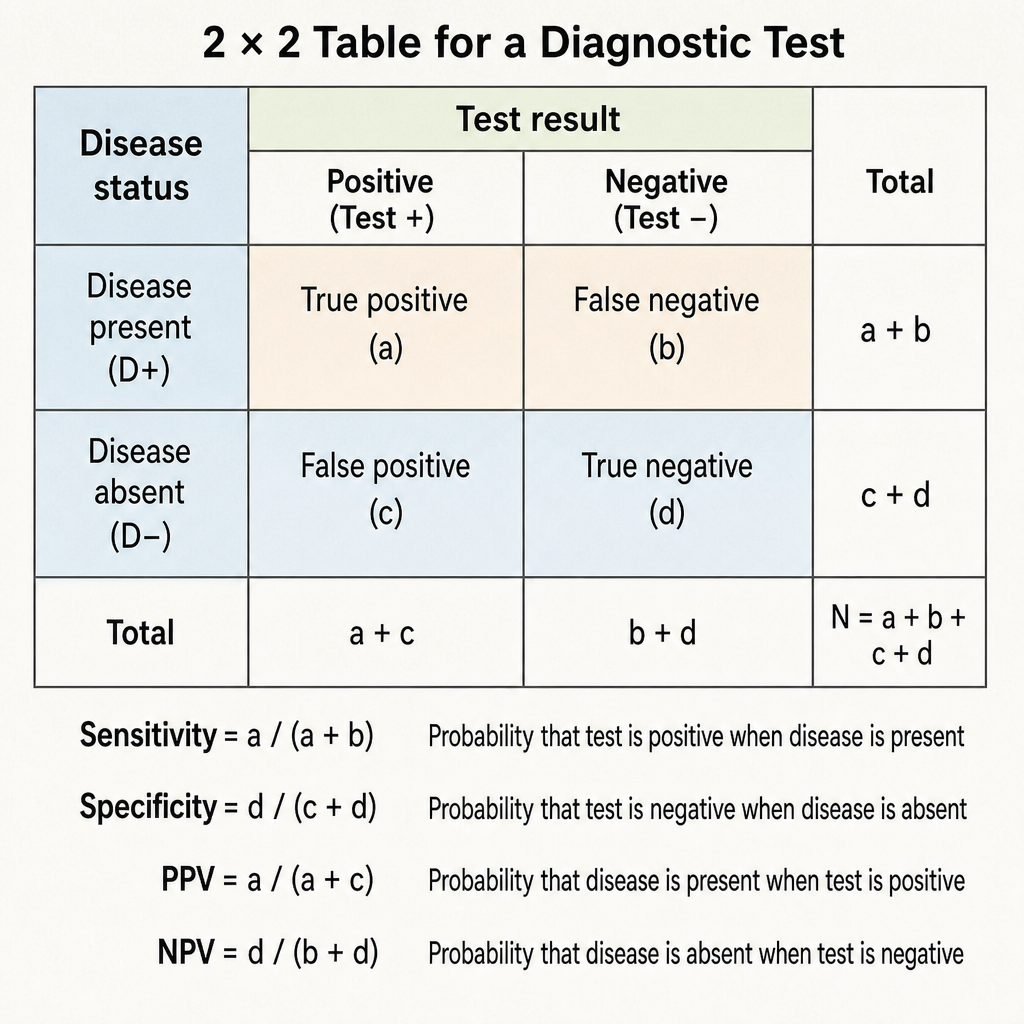
Specificity of a diagnostic test is defined as:
What is the 95% confidence interval for the intraocular pressure (IOP) in the 400 people, given a mean of 25 mm Hg and a standard deviation of 10 mm Hg?
For testing the statistical significance of the difference in heights among different groups of school children, which statistical test would be most appropriate?
All of the following are characteristics of case control study except:
In the context of medical screening, how does a series testing approach affect the net sensitivity and net specificity of the screening methods?
What is the 95% confidence interval in a study with an estimated prevalence of 10% and a sample size of 100, expressed as a percentage range?
STEPwise approach to surveillance for Non-Communicable diseases step 2 is
Most appropriate measure for central tendency when data includes extreme values?
In a village, every fifth house was selected for a study. This is an example of
Which of the following is a non-probability sampling method?
Want unlimited practice?
Get full access to all questions, explanations, and performance tracking.
Scan to download app