
Normal Distribution — MCQs

APGAR scores of 30 children are recorded in a hospital, and most of the readings are found to be 7 or above. What can be inferred about this data distribution?
What is the 95% confidence interval for the intraocular pressure (IOP) in the 400 people, given a mean of 25 mm Hg and a standard deviation of 10 mm Hg?
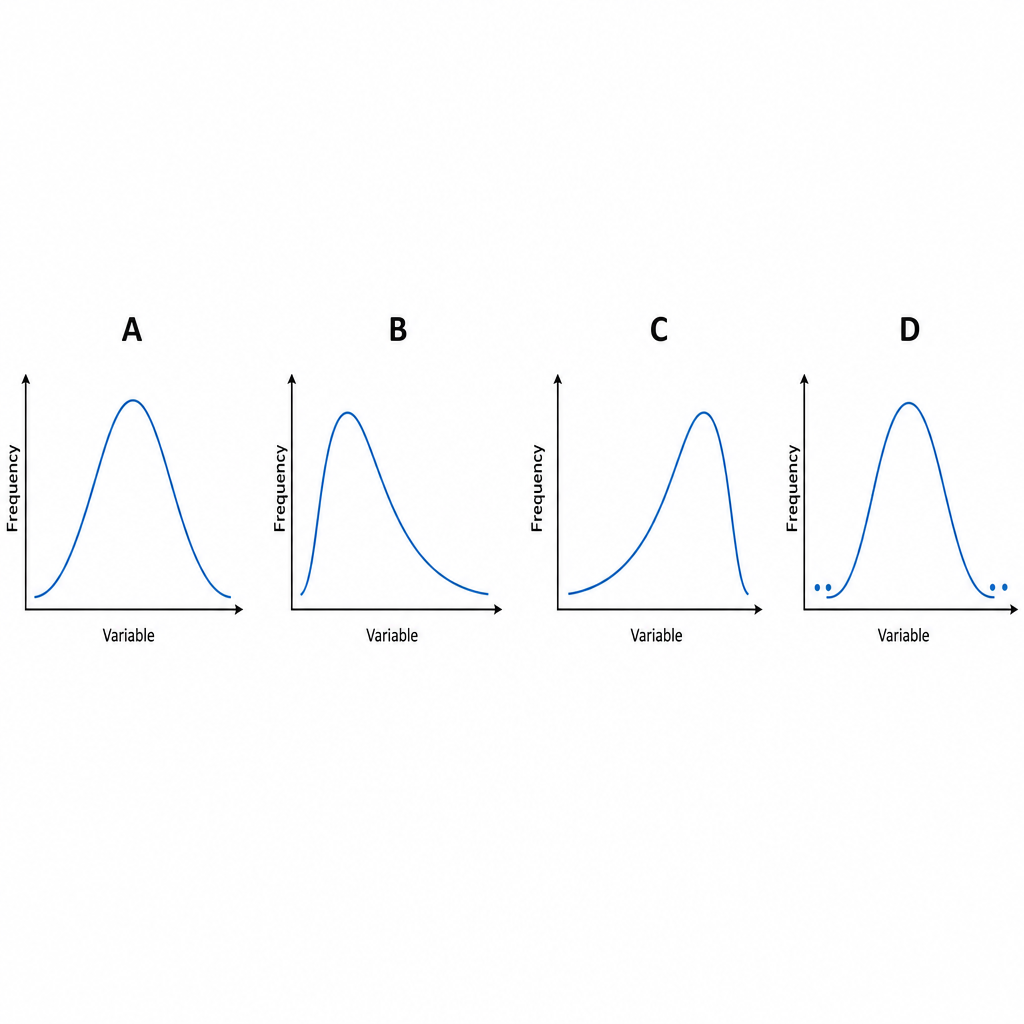
A graph shows four different distribution curves labeled A, B, C, and D. Identify the correct sequence of distribution types shown in the graph.
For a positively skewed curve, which measure of central tendency is largest?
What is the shape of a normal distribution curve?
A study is performed to assess the intelligence quotient and the crime rate in a neighborhood. Students at a local high school are given an assessment and their criminal and disciplinary records are reviewed. One of the subjects scores 2 standard deviations over the mean. What percent of students did he score higher than?
In a normal distribution, one standard deviation from the mean includes approximately:
Which one of the following tests should be applied to compare mean haemoglobin level of two groups of antenatal mothers?
In a normal distribution, Mean ± 2 S.D. contains
In the estimation of statistical probability, Z score is applicable to:
Want unlimited practice?
Get full access to all questions, explanations, and performance tracking.
Scan to download app